
I am grateful that I get the chance to start my Sundays with the free time and leisure to attempt translating poetry.
This Sunday, on 26th April 2026, I woke up with an urge to translate parts of ‘Ae kuch Abr, kuch Sharaab aaye,’ by Faiz Ahmed Faiz, sung beautifully by Mehdi Hasan.
The couplet I started with was:
Kar raha tha gham-e-jahaan ka hisaab,
Aaj tum yaad be-hisaab aaye.
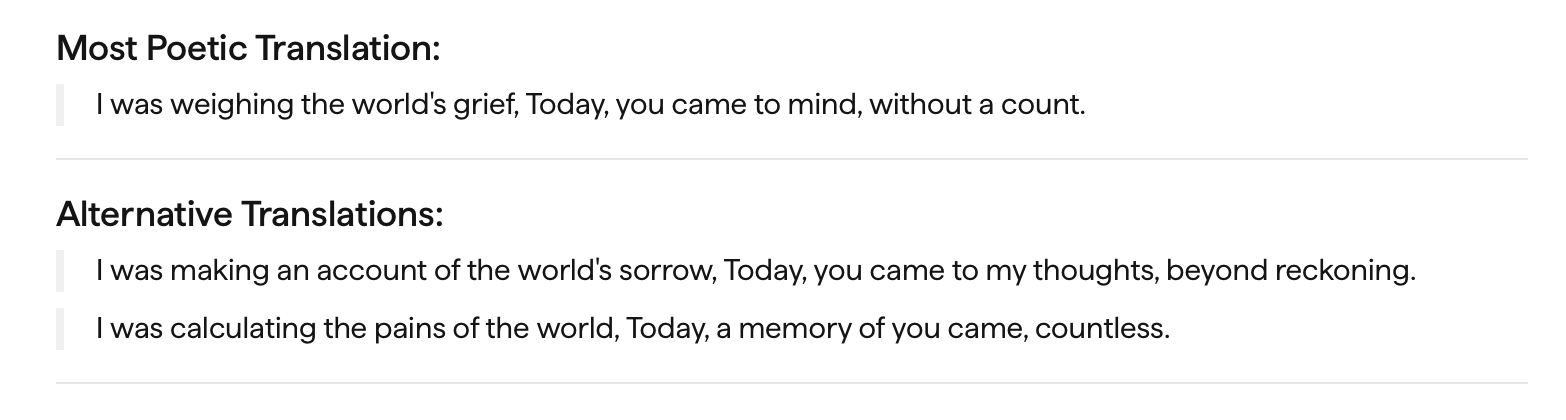
I asked ChatGPT with extended thinking (GPT 5.5) to help me create a graphic I could post on Instagram with this translation, inspired by a similar post I had done before. It generated the following:

It is fair to say that I was dissatisfied with this image and translation. I did not post this, but I did translate the couplet on my own and posted it on my story. My translation for this was:
I was accounting for
the sorrows-of-the-world.
Today, you crossed my mind,
un-countably.
When you look at the two translations side by side, it is immediately clear that neither is semantically inaccurate, but one is more ‘formally lossy’ than the other.
GPT translates ‘yaad aaye’, which in its simplest form means remembering or you came to my memory more passively, as “thoughts of you returned”. That’s a mouthful, I went with the more colloquial “you crossed my mind.”
GPT 5.5 also translated ‘behisaab’ into “beyond measure”, while I went for “uncountably.”
I don’t want to pronounce an objective judgement on which translation is better, and indeed, Sarvam’s model (presumably trained with a greater emphasis on multilingual performance and translation) came pretty close to mine.
But the difference between “uncountably” and “without a count” or “beyond measure” stood out to me.
In the original, much of the couplet’s poetic force is in the interplay of ‘hisaab’ and ‘behisaab’. A simple prefix switches the scene from one of the poet bookkeeping universal sorrows, which are still countable, to the poet remembering an absent beloved in a manner which is essentially uncountable/incomputable.
This essence is lost when you translate the addition of a prefix to a more descriptive phrase like “without a count” or “beyond measure.” Even uncountably only barely captures some of it posited against the accounting for. Unaccountably means something else in English.
This led to the following set of tweets and then into a rabbit hole on poetry translation, language understanding and tokenisation in language models.
Here are some papers that I found (thanks ChatGPT), haven’t read through, but hope to come back to eventually:
- Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data (https://aclanthology.org/2020.acl-main.463.pdf)
- Do Language Models Have Semantics? On the Five Standard Positions (https://aclanthology.org/2025.acl-long.1258.pdf?)
- IOLBENCH: Benchmarking LLMs on Linguistic Reasoning (https://arxiv.org/pdf/2501.04249)
- The Punster’s Amanuensis: The Proper Place of Humans and Machines in the Translation of Wordplay (https://acl-bg.org/proceedings/2019/RANLP_W1%202019/pdf/HiT-IT2019007.pdf?)
- The Translator’s Canvas: Using LLMs to Enhance Poetry Translation (https://aclanthology.org/2024.amta-research.16.pdf)
- How Good Are LLMs for Literary Translation, Really? Literary Translation Evaluation with Humans and LLMs (https://aclanthology.org/2025.naacl-long.548.pdf)
- Evaluation of Generated Poetry (https://aclanthology.org/2025.eval4nlp-1.9.pdf)
- How Tokenization Limits Phonological Knowledge Representation in Language Models and How to Improve Them (https://arxiv.org/pdf/2604.17105)
- ByT5: Towards a Token-Free Future with Pre-trained Byte-to-Byte Models (https://aclanthology.org/2022.tacl-1.17.pdf)
- CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation (https://aclanthology.org/2022.tacl-1.5.pdf)
- CHARFORMER: FAST CHARACTER TRANSFORMERS VIA GRADIENT-BASED SUBWORD TOKENIZATION (https://arxiv.org/pdf/2106.12672)
- CUTE: Measuring LLMs’ Understanding of Their Tokens (https://aclanthology.org/2024.emnlp-main.177.pdf)
- PhonologyBench: Evaluating Phonological Skills of Large Language Models (https://aclanthology.org/2024.knowllm-1.1.pdf?)
- ByGPT5: End-to-End Style-conditioned Poetry Generation with Token-free Language Models (https://arxiv.org/pdf/2212.10474)
- PoeLM: A Meter- and Rhyme-Controllable Language Model for Unsupervised Poetry Generation (https://aclanthology.org/2022.findings-emnlp.268.pdf?)
- Tokenizer Choice For LLM Training: Negligible or Crucial? (https://aclanthology.org/2024.findings-naacl.247.pdf)
- Retrofitting Large Language Models with Dynamic Tokenization (https://aclanthology.org/2025.acl-long.1444.pdf)
- Zero-Shot Tokenizer Transfer (https://arxiv.org/pdf/2405.07883)
- FlexıTokens: Flexible Tokenization for Evolving Language Models (https://arxiv.org/pdf/2507.12720)
My main takeaway from this rabbit hole discussion with my friend and buddy ChatGPT (slightly ironic, but am I?) was that current large language models are great at semantic translation but not great at capturing the phonological and orthographic elements of text in translation.
This is because of a) their limited capability for linguistic reasoning and understanding (specifically compositionality in text) and b) how the paradigmatic sub-word tokenisers do not capture this relevant information.
This is the link to my ChatGPT conversation on this.

