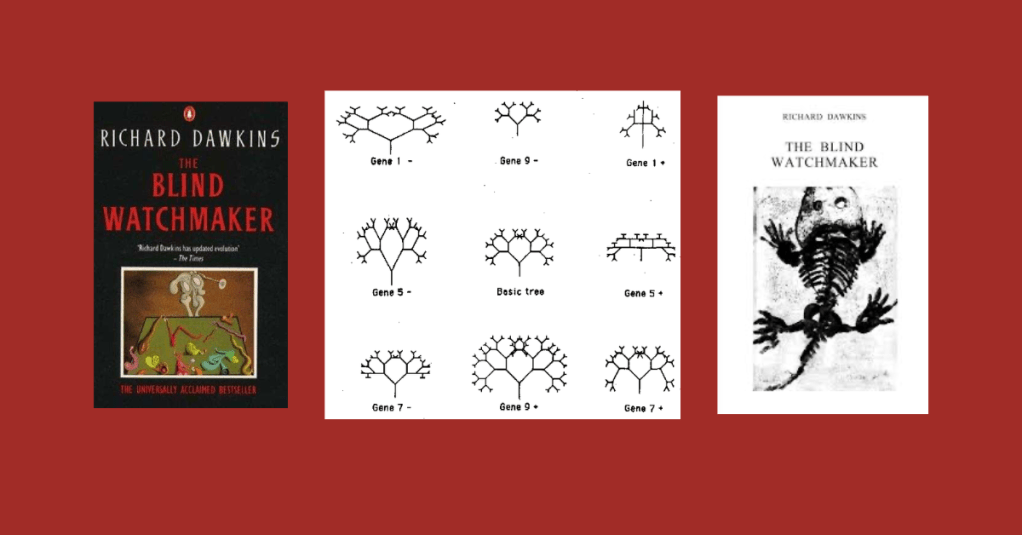
TLDR: Following Richard Dawkins’ description in The Blind Watchmaker, I built a simple computer model demonstrating evolution through separate DEVELOPMENT and REPRODUCTION procedures, where random mutation and non-random selection accumulate changes over generations. The Python code implementing this simulation, including the analysis of gene trends, is available on GitHub.
In chapter 3 of his book The Blind Watchmaker, Richard Dawkins discusses “Accumulating Small Changes” in evolution.
He mentions building a computer procedure DEVELOPMENT and REPRODUCTION and embedding it in a larger computer program EVOLUTION to represent how the smallest of changes can accumulate to large variations over successive generations in a Darwinian way.
Full Relevant Quote from The Blind Watchmaker, Page 56:
“We have assembled our two program modules, then, labelled DEVELOPMENT and REPRODUCTION.
REPRODUCTION passes genes down the generations, with the possibility of mutation.
DEVELOPMENT takes the genes provided by REPRODUCTION in any given generation, and translates those genes into drawing action, and hence into a picture of a body on the computer screen.
The two modules [come] together in the big program EVOLUTION.
EVOLUTION basically consists of endless repetition of DEVELOPMENT and REPRODUCTION.
In every generation, REPRODUCTION takes the genes that are supplied to it by the previous generation, and hands them on to the next generation but with minor random errors — mutations.
A mutation simply consists in +1 or –1 being added to the value of a randomly chosen gene. This means that, as the generations go by, the total amount of genetic difference from the original ancestor can become very large, cumulatively, one small step at a time. But although the mutations are random, the cumulative change over the generations is not random.
The progeny in any one generation are different from their parent in random directions. But which of those progeny is selected to go forward into the next generation is not random. This is where Darwinian selection comes in. The criterion for selection is not the genes themselves, but the bodies whose shape the genes influence through DEVELOPMENT.
In addition to being REPRODUCED, the genes in each generation are also handed to DEVELOPMENT, which grows the appropriate body on the screen, following its own strictly laid-down rules.”
This felt like a great project to do to get some hands on intuition about evolutionary, developmental and reproductive processes at large population and time scales – and build an intuition about Darwinian Selection through cumulative change and random mutation.
First Attempt and the Lamarckian Error
To get started, I listed out all the abstractions I would require to simulate this. These included:
- ENVIRONMENT – A stage on which to act. Could be static or dynamic – went with static for the first attempt.
- AGENT – An object of some preliminary state and behaviour enacted within the ENVIRONMENT.
- DEVELOPMENT – A process by which the agent could act within the environment.
- REPRODUCTION – A process by which agents in an environment could replicate.
- GENES – Encoded information that could influence behaviour in DEVELOPMENT and are passed on with MUTATION in REPRODUCTION.
- GENERATION – One complete run DEVELOPMENT and REPRODUCTION.
- EVOLUTION – Successive runs of GENERATIONS.
In my first attempt at coding this – I got two key things wrong – what Dawkins calls out as being Lamarckian above –
- I interpreted genes as “code” quite literally and instead of writing it as information that enables computation in an environment (BEHAVIOUR during DEVELOPMENT), wrote it as the BEHAVIOUR defining function.
- I passed gene values directly affected by DEVELOPMENT to follow up generations. This was akin to saying that giraffes got longer necks because stretching during their lifetime directly altered their inheritable information, which was then passed on – the classic Lamarckian idea that DEVELOPMENT passes changes back to REPRODUCTION.
“The nature of genes is unaffected by their participation in bodily development, but their likelihood of being passed on may be affected by the success of the body that they helped create. This is why in the computer model, it is important that the two procedures called DEVELOPMENT and REPRODUCTION are written as two watertight compartments.
They are watertight except that REPRODUCTION passes gene values across to DEVELOPMENT, where they influence the growing rules. DEVELOPMENT most emphatically does not pass gene values back in REPRODUCTION – that would be tantamount to Lamarckism.”
Pg 56, The Blind Watchmaker.
Fixing the Error and Final Set Up
But thankfully reading through the text again I recognised my mistake and redid the code. Here is what the final setup looked like:
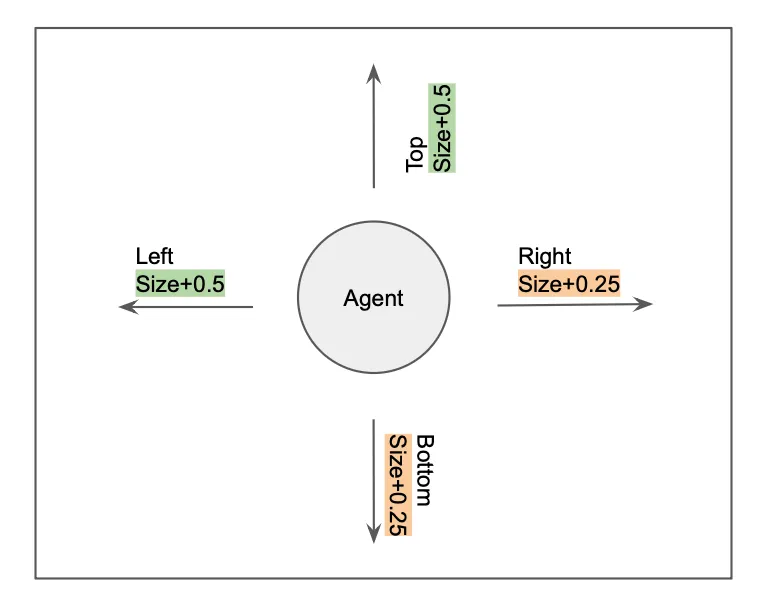
- The ENVIRONMENT was a 2D 5X5 grid.
- Each AGENT was initialised with 5 parameters, but most critically: size, genes.
- In each round of DEVELOPMENT, agents could move left, right, top, or bottom.
- Decision to move was based on weighted random.choice(), where AGENT GENES were weights.
- Based on move direction, the size of the agent would increase by a pre-determined constant.
- At the end of each round of DEVELOPMENT, there would be a check for REPRODUCTION.
- Selection pressures in REPRODUCTION were primarily size and indirectly the external environment.
- REPRODUCTION would only be triggered every five rounds of DEVELOPMENT, and only for agents in top 40% size-wise.
- During REPRODUCTION parent AGENT GENES would be copied and randomly mutated to create the AGENT_child.

Preliminary Observations
To be able to observe the performance, I added print statements for each DEVELOPMENT run that would show the AGENTS in the ENVIRONMENT, their GENES, direction of movement and SIZE.
This meant that I could see both the increase in size of initial agents, as well as, any new child agents that were added through REPRODUCTION.
I also added a final analysis view that included: AVERAGE genes in the ENVIRONMENT at the end of all DEVELOPMENT and REPRODUCTION, as well as, some lineage specific analysis for how each seed agent did in REPRODUCTION.
Here’s a snapshot of the final analysis from one of many runs:

I was happy to see:
- Significant increase in the population from 2 agents only to 12507.
- Slight positive bias for top and left in the weights and negative bias for bottom and right.
- Agent 1 with higher biases for the preferred directions and correct negative biases for the unpreferred directions doing better in the population than Agent 2.
Some future directions, though, are:
- Comparing how different agents do when they start with different weights instead of the same. As you can see the starting weights [1,1,1,1] still remain a dominant strategy.
- Implementing some minimum and maximum survival threshold in terms of size to make sure that the population doesn’t explode exponentially and I can run more DEVELOPMENT and REPRODUCTION runs.

