This post covers the problem discovery, market gap analysis, technical implementation, product evolution, market testing, and future directions of StealthScout. For those interested in the technical details, the complete implementation is available in the project’s GitHub repository. Non-technical readers can skip the “Building The Technical Solution” section.
In an earlier post I had mentioned that from July to September 2024, I worked on building a report generation tool alongside my Editorial Fellowship at Blume Ventures.
After speaking with about 20-25 early-to-mid-stage venture investors, I learned that report generation was not a hair-on-fire problem. If there’s anything I’ve internalized from years of doing 0-1 projects, it’s that you need to be working on painkillers, not vitamins.
This is why I moved on from building that to StealthScout.
The inspiration for this really came when during a conversation with a Partner at one of India’s top ten venture capital firms, they told me that “Report generation is about business and market but at early-stage VC, it’s really about the people.” They suggested I build something that could help with signal extraction for people instead.
This insight led to StealthScout – a tool for tracking potential founders before they start up.
Market Gap Analysis & Problem
Even when I was interviewing folks about the report generation problem, the one common sourcing problem that kept surfacing was that VCs needed better ways to track transitions of senior employees at high-growth firms.
Until then I had dismissed this as a low-level problem that LinkedIn or Hubspot could solve, but hearing it in clear words from a senior partner really got me to see the reality of that insight.
While it might sound trite to say that early-stage venture capital is all about betting on people. And the market had clear gaps in addressing this need.
Tools like Tracxn, Crunchbase, and Dealroom are built for company discovery or market intelligence, not people discovery. Even more niche data platforms like Synaptic also only offer people search as an additional feature. I guess this is because the money is the real data money is in serving later-stage private market investors.
Apollo, Zintlr and similar tools exist but they are designed for B2B sales folks. LinkedIn and its platform of tools focused primarily on recruitment. Besides Harmonic, the space was fairly unexplored. This was intriguing.
Another big barrier, and possibly the main one, to a tool like this was LinkedIn itself. It’s hard to start anywhere else for an endeavor of this sort. In many ways, there is no competitor to LinkedIn and its talent graph of the white-collar workforce (almost globally). Anytime I met someone they would complain about not being able to do anything with LinkedIn API / data.
There’s a reason why investors still rely on scouts – a somewhat outdated version of talent tracking technology. Hey, but sometimes constraints create opportunities. With these insights and limitations in mind, I decided to build StealthScout.
Building The Technical Solution
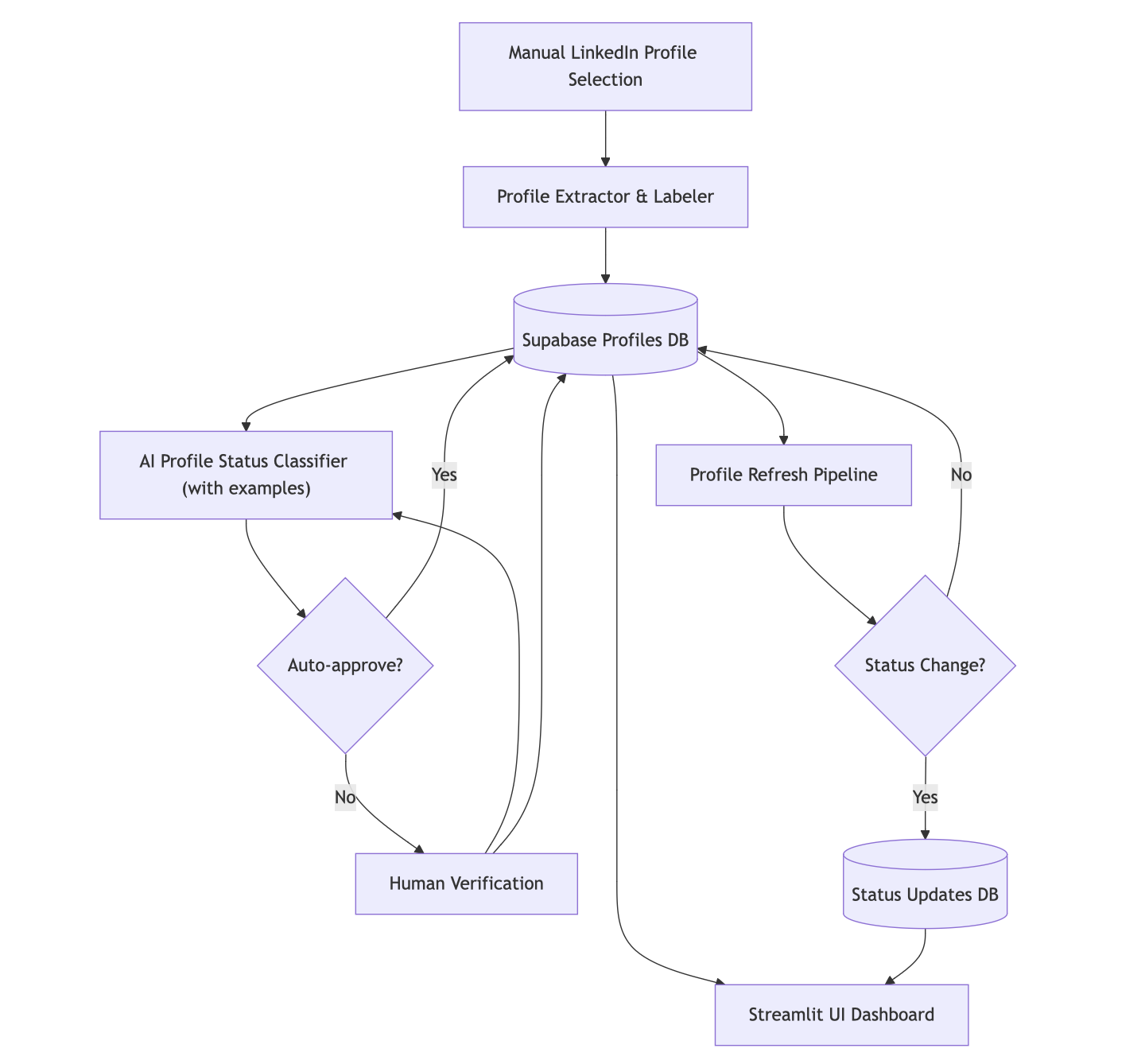
1. Setting up a backend
It started simple. I found a LinkedIn API that worked well for extracting profiles of stealth founders from specific companies, which I could then showcase to my 3-5 early testers. This project marked my first time setting up a Supabase database, which was exciting but challenging.
I had to come up with a data model and had to work with tables, foreign keys, and relations all of which was new territory for me.
While functional, the database structure still has room for improvement, particularly in how company names are handled. Currently, retrieval depends on a static manually-entered key in the search_company field, causing duplication issues. A better solution would be a dedicated companies table that relates to individual experience entries.
2. Setting up labelling and filters
This was the first way I created value with the product – by curating a list of stealth founders in one simple to-search database.
Beyond this basic curation though, I also learned that there was value in building specialized filters for signals that VC investors would look for.
Generic filters like years of experience and role titles, function titles, etc are great for something like recruitment and sales but are not targeted for the things that VCs would look for – such as say being a repeat founder, or senior operator, or leading cross-functional teams and so on.
To make this happen, I extended the profile extraction and insertion pipeline into a labeling pipeline focusing on a) profile status classification, b) extracting role highlight, and c) checking if ‘repeat founder’ or ‘senior operator’.
I started by manually labeling about 20 profiles before implementing an automated LLM workflow where human approval was only needed for edge cases. This made my life much easier, allowing me to scale from 100-200 profiles to over 600 and now 1000 quickly.
While repeat founder, role highlights, and senior operator checks were simple to implement, profile status classification was a bit more challenging. I could foresee many edge cases here and to avoid errors I have made before I made sure I was capturing all human-in-the-loop reviews in a comprehensive examples library.
This has now grown into library of 200+ examples covering various edge cases – like profiles where headlines were updated but work experience wasn’t, or senior operators who were unemployed but active as angel investors. As Vaibhav from Better Capital describes it, it felt like “the software using me” to train itself.
3. Setting up the front end and user experience
Over the course of my user research for Dealey (as well as StealthScout) I had learned that the boxy, cumbersome interfaces of most data applications (think Tracxn, Crunchbase, Apollo or LinkedIn Premium) is one of the main problems that many folks have with these products.
This is why I knew that I had to spend some time mapping out what I should include in the front end and what not – highlighting the most relevant information for investors.
I included detailed profile views showing experience, education, and custom labels, but also made sure to tag the profiles at the top so that searching through the data became simpler.
This showed in the feedback I got where at least 3 of the 10 early users got back saying that the UI made using the product more fun and not having to skip between windows to find information was great.
For a detailed look at the technical implementation, check out the project’s GitHub repository and documentation at https://github.com/dhruvtre/StealthScout-Public.
Product Evolution

After speaking with data companies like Synaptic and Zintlr, I realized I couldn’t compete on a database scale alone. This is when I toyed with the alternative ‘positioning’ (hyperbole lol) of promising updates on talent status, rather than a database of founders.
This is a fine difference but it was exciting for me to discover it because one alert is more valuable than one profile. An alert is an actionable insight, while a profile is just a static piece of information, a data entry, that pops up on a webpage (mostly to be recorded until actionalized into insight in a CRM or a Deal Management System in the case of VCs).
Until then I would always get questions about the volume of profiles, but once I made the change, the questions became more about what profiles were being tracked. I could have a smaller but more complete, and niche quality data set to offer with high value updates.
This also meant that I could move on from having to curate stealth founders and instead batch tracking current employees and see if they would quit or move to “stealth” or become a “founder.”
The technical implementation involved enhancing the profile refresh pipeline to detect meaningful status changes and store them in a separate updates table. Each alert would capture the change, especially in work experience, and then record a move from one profile status (as classified in the labelling pipeline) to another.
This had its scaling challenges too though. In my experience over the last three months, I have seen less than 2% total rates of change in status, and of this, less than 1% are relevant to investors. This means that in a data set of 1000 profiles you can at best hope for 10 transitions every week – and this is the best-case scenario.
Most senior operators, repeat founders, and high-potential talent, are fairly stable in their careers and there aren’t many week-on-week changes.
I am now experimenting with selection criteria to increase the signal-to-noise ratio – targeting specific industries during active periods and companies with historically high founder output.
Market Testing and Learning
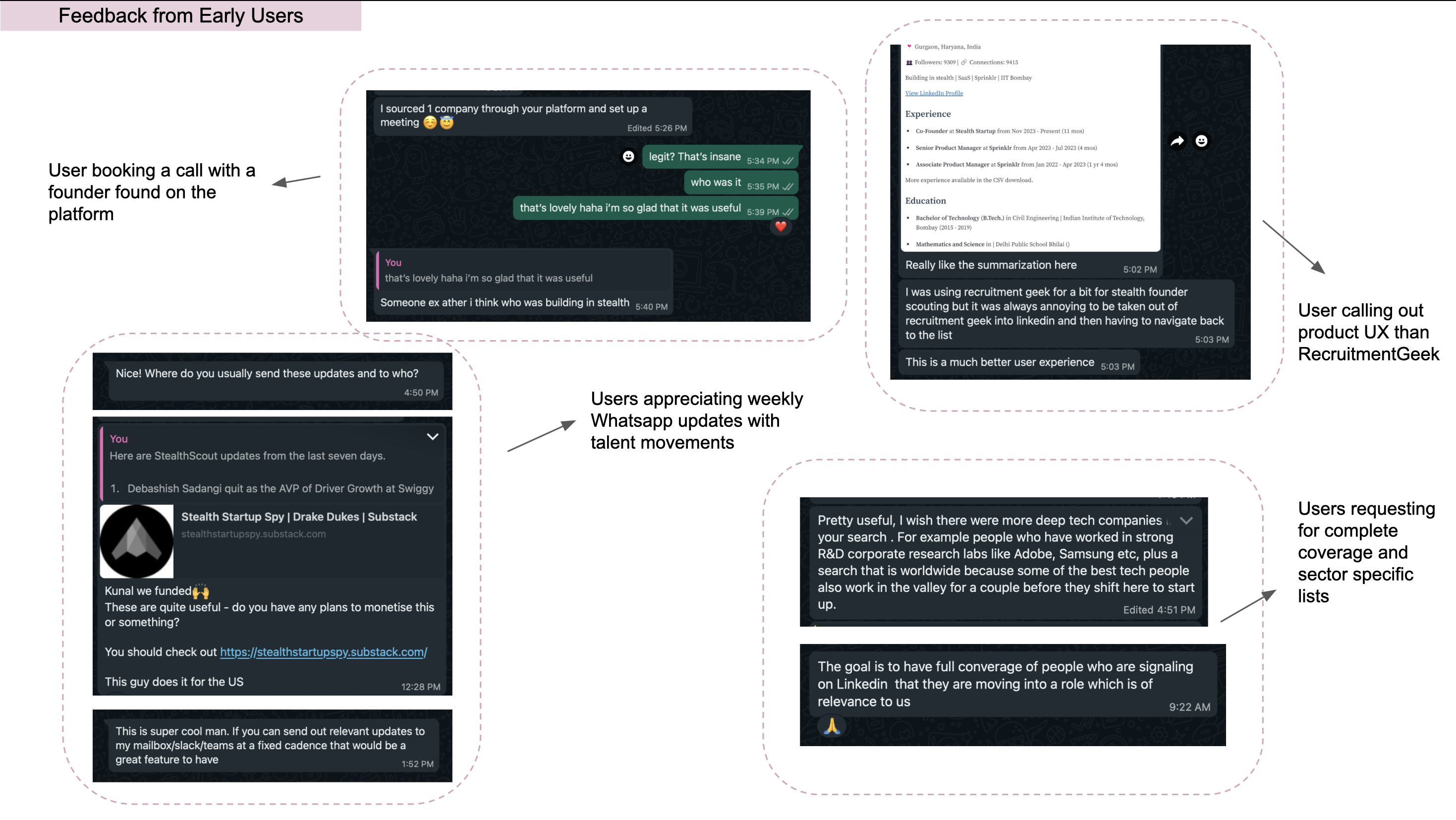
The product received positive feedback from early users, particularly around the UI and alert functionality. However, testing revealed three key insights that convinced me that while this was more hair on fire than report generation, this problem still was not hair on fire enough.
1. Data Limitations: The offering was fundamentally capped by our data sources. Without proprietary data collection efforts, we would always be competing with LinkedIn Premium and similar tools. (1)
2. Market Context: Unlike more mature venture ecosystems, India’s venture landscape relies heavily on personal networks – employees often raise funding from their employer’s investors, and analysts regularly exchange deal information through private channels. This makes proprietary information particularly valuable, as VCs compete for “alpha” in a market where successful outcomes are still relatively rare.
3. Discovery Patterns: Outbound or discovery on LinkedIn still forms for less than 20% of most early-stage investors I spoke to spare a few who are more and more early – nearly pre-seed or in the -1 to 0 to 1 phase – in which case the core use case isn’t discovering founders to invest in as much as founders to nurture – so that’s a bit different.
But don’t get me wrong, I remain convinced that a centralized talent intelligence platform for early-stage investors would improve capital allocation efficiency. The current reliance on fragmented information networks creates information asymmetries that benefit established players but may not lead to optimal funding outcomes.
Future Directions and Learnings
While StealthScout hasn’t attracted paying customers yet (3), but just being able to find a reliable profile extraction API and building a functional system that users found helpful was rewarding in itself.
Some future areas of focus for me with this (alongside experimenting with getting people to pay for this) are:
1. Scaling data coverage – Expanding beyond the current 1,000 profiles to increase alert frequency
2. Pattern analysis – Mining insights about founder transitions (which companies produce more founders, typical stealth-to-public timelines)
3. Source diversification – Adding alternatives to LinkedIn, particularly for Deep Tech sectors where LinkedIn coverage is limited. (2)
4. Predictive modelling – Developing career trajectory insights to anticipate transitions before they occur, and more fun things around career trajectories.
Notes:
- (1) I also learned so much about why businesses like Crunchbase are all “people heavy” businesses. There’s a full tangent on what private intelligence networks are and how they enable private markets – but that’s for another blog post.
- (2) More and more interesting people are not on LinkedIn. I don’t have the numbers for this and I can probably find them on Perplexity but I am confident that not more than 30-40% of the total Indian white-collar workforce would be on LinkedIn. And any classification of white-collar workforce will be minuscule relative to the total population.
- (3) Personal Learnings on Monetization – Despite having 5-7 regular users who found clear value in the product, I hesitated to ask them to pay. This led to confusion about whether this should be a platform I sell to funds or a product I sell to analysts and a delay in validating the business model sooner. There was also clearly value being delivered, but I guess it’s a personal hurdle to get over, to ask for money, and not get lost in numbers bigger than I can fathom too soon. Thanks to kind folks in the space who have been giving me feedback, I learned that if value is being created, I must also learn how to capture it.

