Origin Story
In Q324, I had narrowed down on building tooling for private market investors (private equity and venture capital analysts).
I had already experimented with a linear company research workflow by then that I’ve described here.
My bet was that similar company research would be useful for private equity and venture capital investors.
I already knew many friends from Ashoka, and Ramjas now worked in back-office research and knowledge management roles at large auditing, management consulting, or investment banks.
However, company research for VC/PE investors requires more depth than company research for discovery calls.
Understanding the Problem Space
As I spoke with more users about their venture research process, I realized that there was something common across doing “research” to create thesis documents, company notes, prepare for a founder call, or post on social media.
This was tool use, scraping, and reading—but different documents required different customizations.
Some specific tasks that came up in my chats with analysts were:
- Specific tools for specific types of information
- Cross-referencing information from various sources and picking the one that seems most reasonable
- Combining different data points to compute an aggregate one
This meant that I would definitely need more tools than just Google Search. I would also need a way to gather information from various sources before I worked on creating the final output.

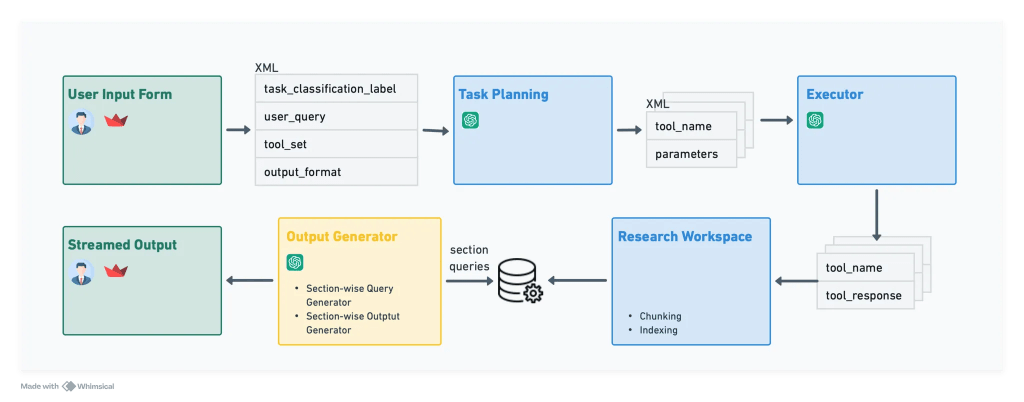
Technical Evolution – Initial Architecture Inspiration (AutoGPT, BabyAGI, OpenDevin)
I came across the Auto-GPT, BabyAGI, and OpenDevin architectures at this point. I figured it would be nice to go this route.
What was exciting about all these architectures was that they were one layer of abstraction up from one specific ‘workflow.’
Using a separate task creation and execution agent and having a tool library and a task library would help me build a more intelligent report generation system.

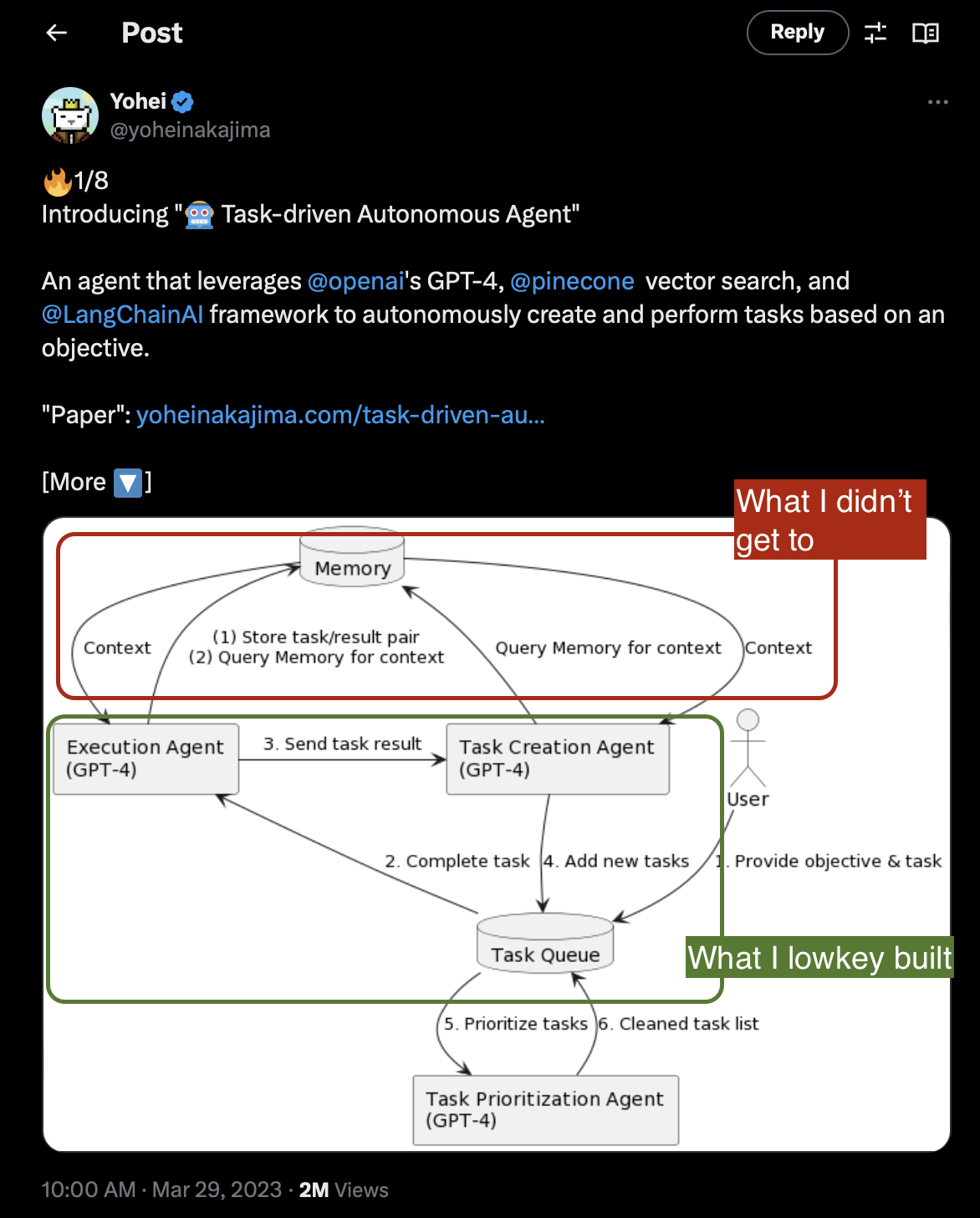

Technical Evolution – My Implementation
Sadly, I wasn’t able replicate the entire architecture before I realized this was not a significant problem for early-stage VCs, the target customers I wanted to build for.
What I did manage to do was create a simpler system that took in user input to create one of two kinds of reports: industry overviews or company profiles.
The system could get information from multiple sources, chunk the content, and generate relevant report sections using a query engine.
While not as sophisticated as initially planned, it served as a good starting point for understanding the challenges of automated research and report generation.
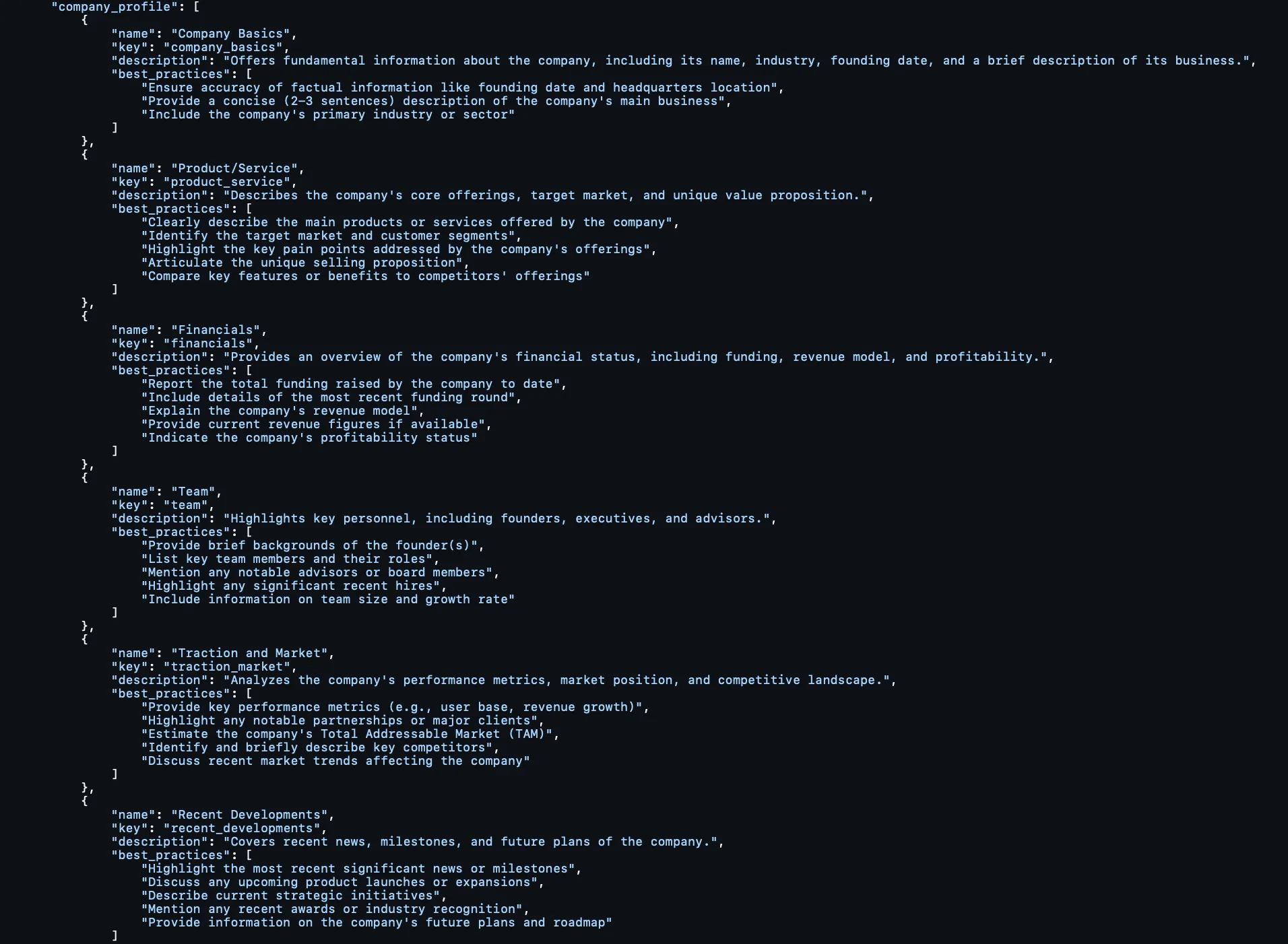
Modular Section / Template Library
What I liked about my approach back then was building out the report output – not as one static template inputted into a prompt window – but as a dictionary – not only of report formats – but at the level of sections.
My reasoning for doing this was twofold:
- This would be a great way to scale the report generation system within an organization across functions and types of reports.It would be good to build more examples eventually.
- I was excited to see if section-specific instructions could be pulled up. It would also be good to make the report generation more modular by allowing users to choose which sections to include within and across reports generated.
This worked because I implemented a task classification task that generated a label and pulled in any custom instructions, tool sets, relevant output templates, etc. Eventually, I moved to a multipage setup on Streamlit, which made this irrelevant.
Much of this was inspired by Jason Liu’s thinking about report generation and template libraries from last year.
Here’s what these report and section templates looked like:
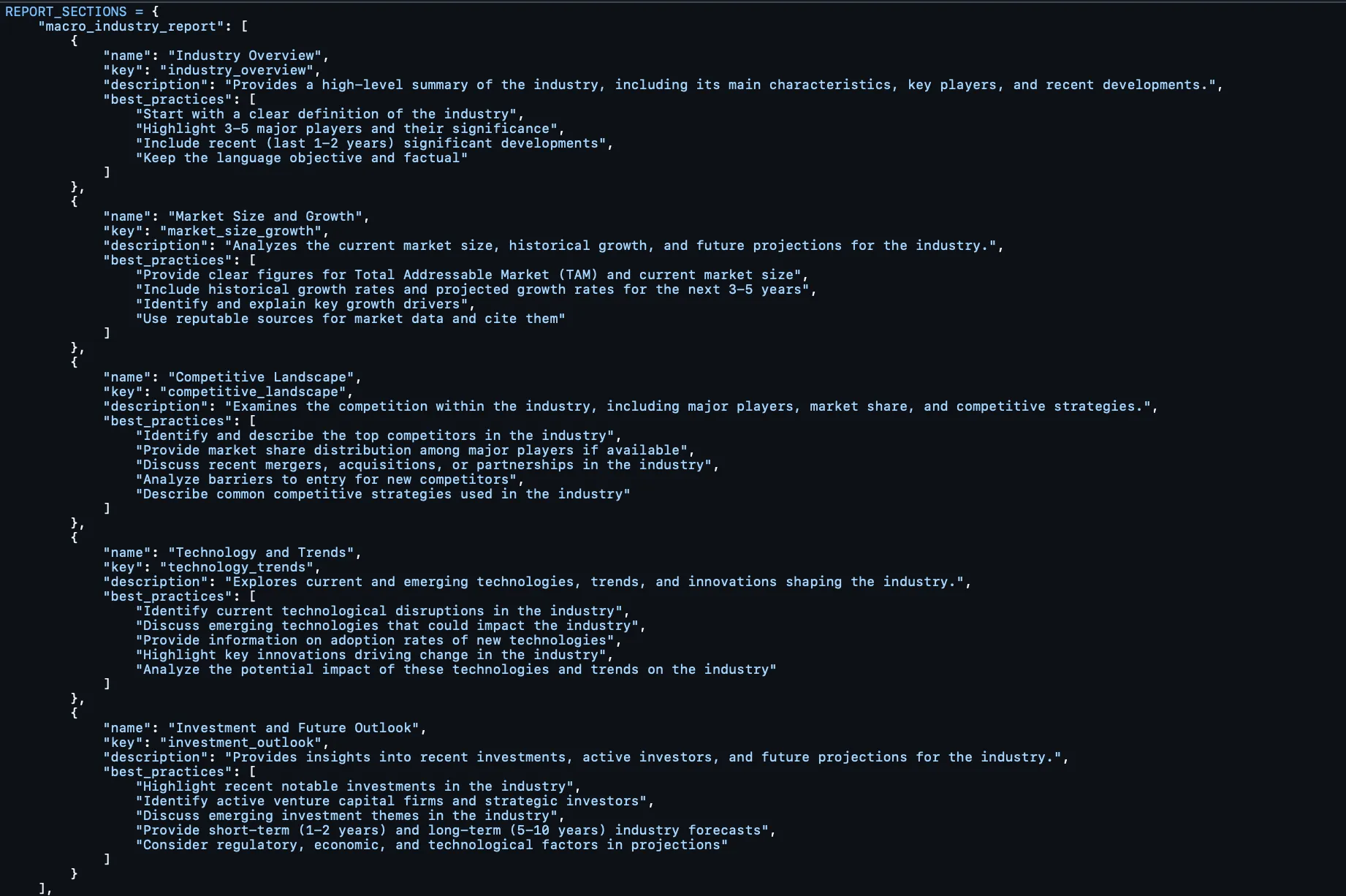
Tool Library
I experimented with building a library of tools to eventually build a nice matching system for the kind of section being researched and the list of tools to retrieve for the agent to research.
However, because I didn’t understand data pipelines, I didn’t consider how to standardize the output from different tools and invest in building schema, validation, etc.
Chunking and Querying
I used a standard chunking and query engine, which was nothing fancy because this worked fine.
After feedback on earlier versions, I added metadata to chunks to include citations in the final output, which worked neatly.
I was very happy when this worked for creating the report and discovering valuable resources.
One such instance was when I created a report on Eldercare in India, and the tool retrieved Blume VC’s thesis on it, and another was when I wanted a report on LlamaIndex and it pulled in all relevant major announcements from the company’s blog.
More technical details are available on the project’s readme here.
Key Learnings
This was also from when I was not coding, pushing to git, etc.
It’s weird, but I think maintaining the various iterations of this report generator/researcher project locally revealed the importance of Github to me. I still have a comment from my failed attempts at tracking commits manually with # comments.
Another fun unlock I have since become more fluent with is building a few-shot example library to make the examples shared with the LLMs more relevant to what I need them to do.
I didn’t have the discipline for this earlier, so I would make what I thought was a representative enough set and plug it into the task prompt. In my later and more recent project (StealthScout), I could implement a data regularisation pipeline, pulling up custom examples, etc.
Reflection and Future Directions
I never got to implement Reflection because of user feedback and increasing technical complexity.
Plus, I don’t think I fully understood what building agents was back then. I was learning to both program and build agents at the same time, and where programs ended and agents began was unclear to me – and in some ways – it remains so, but I am less concerned with the difference now.
My central learning from this project, I think was realizing that while I was obsessed with this report generator use case, it wasn’t what the users I wanted to build for wanted.
Report generation in a VC/PE firm serves different purposes from what it does in organizational communication. This research is the work.
While all users would appreciate support in doing this, it is also, at best, a secondary KRA for most folks in VC/PE who are judged far more by their ability to bring in deals than, say, due diligence or shaping investment theses.
That’s usually something that the Partners are more into, and at that stage, getting information is less a research problem and more a problem of speaking to the right person.
Hey, the good thing is that while I didn’t get to building the “autonomous” prioritizing, memory-having, reflective agents that I set out to – I did say touch along the same lines as LlamaReport.
The main difference here is that Llamareport allows you to upload your sources. In contrast, I was trying to combine the report generation with the research, though looking back, they feel like two completely different systems.
Task context, template instructions, template source, and section dictionaries are similar concepts/abstractions, so that’s nice.

