
Problem Identified:
As someone who has worked in Generalist roles throughout his career, one of the main tasks I’ve done is researching companies before important calls and meetings.
Along with this, I’ve also had to research companies to:
- Do competitor and market research – track or analyse how companies in the space are positioning themselves while shaping our own messaging or to identify potential for partnerships;
- Set up informational and product discovery interviews – speak with folks in specific roles from specific organisations to learn more about their days, workflows and challenges;
- Build lead lists and segment ICPs – especially while doing B2B email or socials outbound, which now requires a great degree of personalisation to stand out in the noise.
Barring a few customizations, I did the same repetitive process each time I researched a company for all the above usecases.
There are only so many things you need to know about the business of a person you’re getting on a call with so that you reach out learn more directly from them.
This process is much simpler if you only work with public companies, but since I’ve mostly always been in startups, finding reliable information about the company can be challenging and all over the place.
It takes time to structure the unstructured information from various sources and make it useful. This is why I figured it’d be nice to build an AI workflow for this.
Solution Imagined:
Here’s a high level design of the system.
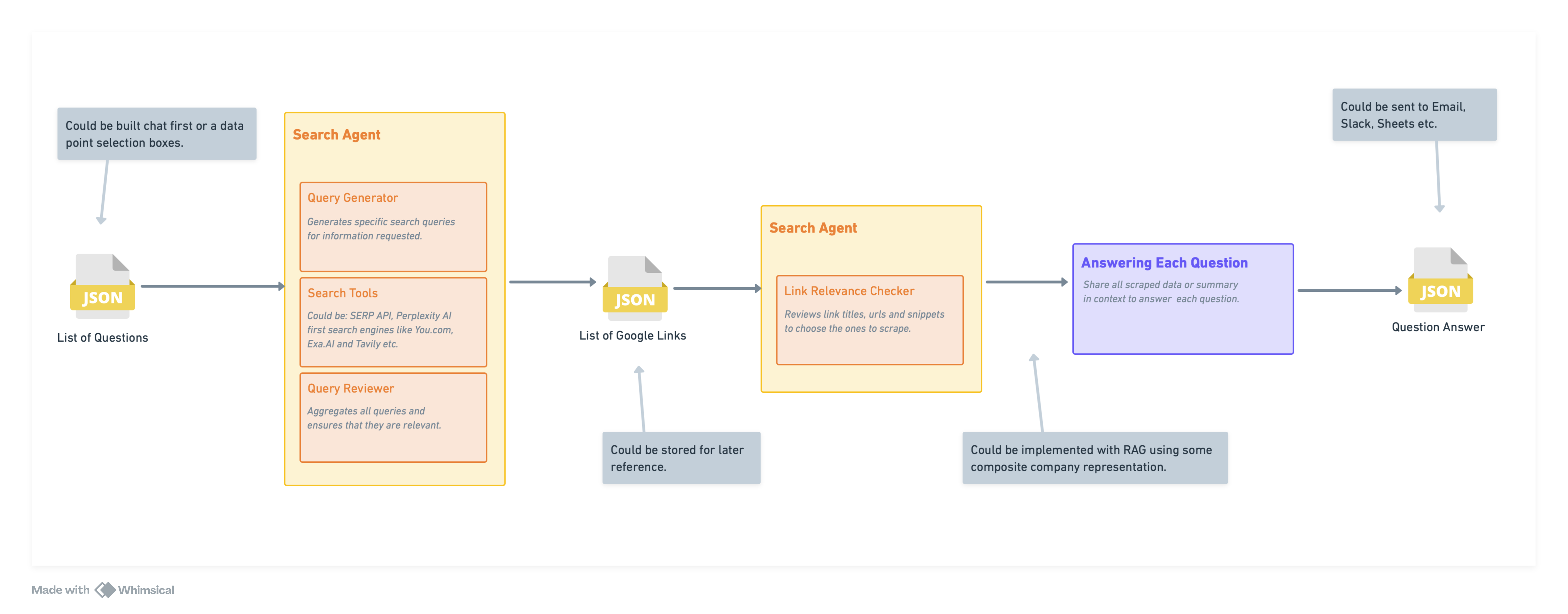
Some things to note about this are:
- I used GPT-4-turbo for most of my experimentation because it came out as the smartest model overall. However, I tried out cheaper models like Anthropic’s Opus, Haiku, and OpenAI’s GPT-3.5-turbo, and each of them worked fine; they just needed prompt adjustments.
- The input is a fixed set of questions you want the AI workflow to answer for a company.
- The only search tool added to the search engine here is a SERP API that pulls up the top-k results with link titles, URLs, and snippets.
- The link relevance checker before the scraping step avoids unnecessary scraping. Feedback to this could also help with building a more robust search engine in the future.
- The output for this flow was the answers to each question. When I implemented it, I set it up to download a report document and update my Google sheet for research.
Levers of Personalisation:
There are various ways to adapt the above workflow to yield more value. I have experimented with a few of these, and each has improved performance.
Some ways to personalise or adapt the workflow above are:
- Introducing more search tools – I set up a simple SERP API for the first implementation, but you could much more simply set up a similar application with Perplexity API (comes with its pros and cons I think).But, adding more tools can mean:
- Optimising the tool-use and link relevance checker—Even at zero-shot prompting, given the search context and search engine system prompt, the relevance checker did a pretty good job eliminating unnecessary SEO items. Adding a few shot examples here is an area I am very excited about because it’s almost like transferring your taste and judgment of information sources to your systems.
Some future implementation improvements:
- Building a highly personalised search agent – Further refine and fine-tune the query generator, relevance checker, and tool use capabilities, leveraging techniques from papers like Stream of Search (SoS): Learning to Search in Language paper.
- Making tool use and choice more autonomous – Implement a more rigorous logic of tool selection and use through function calls, using the OpenAI API and techniques like Chain-of-Abstraction from here.
- Moving beyond data aggregation (gathering and summarisation) to handle lower-level inference tasks, such as judging data validity across sources, clustering, and generating tags for clustering tasks of greater complexity like company operating models, positioning etc.

